Read Time:
How Does AI Candidate Screening Work? FAQs


Pull up your last hiring review deck. Count how many CVs your team reviewed to fill your last ten roles. Now count how many of those candidates actually made it to a first interview. If the ratio is worse than 10:1, you already have a screening problem — and it's costing you more than time.
AI candidate screening promises to fix that ratio. But the gap between what vendors claim and what the technology actually delivers is wide enough to make any experienced TA leader skeptical. This FAQ guide cuts through the noise. It answers the questions that hiring managers and talent acquisition leaders at Indian mid-market and global companies are actually asking in 2026 — from how the scoring works to where it fails, how it connects to your ATS, and when the 3-level model produces shortlists that are genuinely interview-ready.
The most common misconception about AI candidate screening is that it's sophisticated keyword matching. It isn't — or at least, it shouldn't be. Early-generation applicant tracking systems did work that way: scan for the word "Python," count occurrences, rank accordingly. That approach was easy to game and produced shortlists that looked good on paper but wasted everyone's time in the room.
Modern AI screening uses natural language processing (NLP) and machine learning models trained on large datasets of real hiring outcomes. The system learns not just what words appear on a resume, but what combinations of experience, tenure, role progression, and skill signals actually predict a strong hire for a given job category. That's a fundamentally different capability, and it's why the accuracy benchmarks between old-style ATS filtering and genuine AI screening are so far apart.
For TA leaders at Indian companies hiring across multiple geographies, this distinction matters even more. A keyword-based screener trained on domestic hiring patterns will systematically undervalue candidates with international experience, non-linear career paths, or qualifications from institutions it doesn't recognise. A well-trained AI model handles that variation far better. The sections below explain exactly how, and where the limits still are.
When a resume enters an AI screening system, it goes through several processing layers before a score is assigned. Understanding those layers helps you evaluate whether a vendor's claims are credible.
Parsing: The system first extracts structured data from unstructured text, job titles, company names, tenure, skills, education, certifications. Good parsers handle varied formatting, multiple languages, and non-standard layouts. Weak parsers lose data when a candidate uses a creative CV template or a non-Latin script.
Contextual interpretation: This is where AI diverges from keyword matching. Rather than simply checking whether "project management" appears, the model interprets context. A "project manager" at a 10-person startup for eight months reads differently from a "project manager" at a 5,000-person engineering firm for four years, even if the title is identical. The AI assigns weight based on role context, company scale signals, and career trajectory.
Multi-dimensional scoring: A well-built screener scores across several dimensions simultaneously: skills match against the job requirement, depth of relevant experience, seniority alignment, career progression signals, and role-fit indicators. Each dimension is weighted according to the job category. A senior finance role weights tenure and progression heavily; a technical specialist role weights specific certifications and tool proficiency more.
CBREX's C Screen tool is trained on over 250,000 anonymised resumes across 570+ job categories. That breadth of training data means the model has seen enough variation in how strong candidates present themselves, across industries, geographies, and seniority levels, to score with meaningful accuracy rather than pattern-matching against a narrow template. The result is a ranked shortlist, not just a filtered list.
Accuracy claims in AI recruitment tools deserve scrutiny. "98% accurate" sounds impressive, but accurate at what, exactly? There are two distinct accuracy questions worth separating.
Parsing accuracy refers to how reliably the system extracts the right data from a resume. A well-built parser should achieve 95%+ on standard CV formats. This is the easier problem to solve and the one most vendors lead with.
Screening accuracy, whether the system correctly identifies candidates who would perform well in the role, is harder to measure and far more important. It requires comparing AI shortlists against actual hiring outcomes over time. Vendors who can point to outcome data (not just parsing benchmarks) are the ones worth taking seriously.
For context: research on human resume review consistently shows that unstructured human screening is highly inconsistent. Studies have found that the same resume reviewed by two different hiring managers produces different outcomes more than 50% of the time. AI screening, whatever its limitations, applies the same criteria consistently across every candidate. That consistency alone reduces a significant source of quality variance in most hiring pipelines.
Where AI genuinely outperforms human review: speed (hundreds of CVs processed in minutes), consistency (no fatigue, no mood effects, no recency bias), and volume handling. Where human judgment still wins: reading between the lines of a non-linear career story, assessing cultural fit signals, and evaluating candidates for roles where the job description itself is imprecise. The honest answer is that neither is sufficient alone, which is why the hybrid model matters.
For a deeper look at what accuracy benchmarks mean in enterprise hiring contexts, see our post on AI Resume Screening: How to Choose the Right Tool in 2026.

This is the question that should be on every TA leader's checklist when evaluating an AI screening tool, and it's the one most vendors answer least satisfactorily.
AI models learn from historical data. If that historical data reflects biased hiring decisions, favouring candidates from certain universities, certain companies, or certain demographic profiles, the model will learn to replicate those patterns. It won't do so consciously; it will simply weight the features that historically correlated with "successful hire" in the training data, even if those features were proxies for bias rather than genuine predictors of performance.
The most common bias risks in AI screening include:
How responsible vendors manage these risks: The most effective mitigation is anonymisation at the training data level, removing names, photos, addresses, and other demographic signals before the model learns from the data. Structured scoring criteria (explicit, auditable dimensions) also reduce the risk compared to black-box models that can't explain why a candidate scored as they did.
C Screen is trained on anonymised resume data, which removes the most direct demographic signals from the learning process. The scoring dimensions are explicit and auditable, hiring managers can see why a candidate ranked where they did, not just what their score was. That transparency is important both for bias management and for building trust in the shortlist.
When evaluating any AI screening vendor, ask these three questions: What was your training dataset, and how was it anonymised? Can you show me the scoring dimensions and their weights? Do you conduct regular bias audits against actual hiring outcomes?
The comparison isn't binary. The question isn't "AI or human?", it's "which tasks should AI own, and which should humans own?"
Here's a practical breakdown:
This is why the 3-level screening model, agency pre-screen, then AI validation, then stack ranking, outperforms either approach alone. The agency pre-screen applies specialist human judgment to filter for role fit and reach passive candidates. The AI validation layer then scores and ranks the pre-screened pool consistently. The hiring manager receives a stack-ranked shortlist of candidates who have passed both filters. That's a fundamentally different quality of shortlist than either AI-only or agency-only processes produce.
Any honest assessment of AI screening has to include its failure modes. Here are the ones that matter most for TA leaders making real hiring decisions.
CV gaming: As AI screening has become more common, a cottage industry of "AI-optimised CV" services has emerged. These services help candidates stuff their resumes with keywords and phrases that AI screeners reward. The result is CVs that score well but don't reflect genuine capability. This is a real problem, and it's one reason why the agency pre-screen layer is valuable. A specialist recruiter who has spoken to the candidate can flag when a CV has been artificially optimised.
Non-linear career paths: AI models are trained on patterns. Candidates with unconventional career trajectories, pivots, gaps, portfolio careers, entrepreneurial stints, often score lower than their actual capability warrants. This is particularly relevant for senior roles, where the most interesting candidates frequently have non-standard backgrounds.
Niche and emerging roles: An AI model trained on 250,000 resumes across 570 job categories has seen a lot. But for genuinely new roles, AI ethics officer, quantum computing specialist, synthetic biology researcher, the training data is thin. The model's scoring for these categories is less reliable, and human specialist judgment becomes more important.
AI-written CVs: In 2026, a growing share of candidates are using generative AI to write their resumes. These CVs are often well-structured and keyword-rich, which means they can score well on AI screeners regardless of the underlying candidate quality. This is an emerging challenge for the entire industry, not just one vendor.
Job description quality: AI screening is only as good as the job requirement it's screening against. A vague or poorly written job description produces a vague scoring model. Garbage in, garbage out, this applies to AI just as much as it applies to human review.
Understanding these failure modes helps you design a screening process that compensates for them, which is exactly what the 3-level model does.
For most enterprise TA teams, the practical question isn't whether AI screening works in isolation, it's whether it works within their existing tech stack. Most Indian mid-market and enterprise companies already have an ATS in place, and adding a new screening layer needs to fit that infrastructure without creating a parallel workflow.
There are two main integration approaches:
API-based integration: The AI screening tool connects to your ATS via API, pulling candidate data in and pushing scored results back. This is the most flexible approach and works with most major ATS platforms. The candidate experience is unchanged; the screening happens in the background.
Native ATS modules: Some ATS platforms have built AI screening capabilities directly into their product. These are easier to set up but often less sophisticated than dedicated AI screening tools, and they lock you into the ATS vendor's AI roadmap.
Common ATS platforms used by Indian enterprises, including Workday, SAP SuccessFactors, Keka, Darwinbox, and Zoho Recruit, all support API-based integration with external screening tools. The key questions to ask any AI screening vendor are: Does your integration require custom development, or is it plug-and-play? How does data flow between systems? What happens to candidate data after screening?
CBREX integrates with all major ATS platforms without replacing them. The workflow is additive: agencies submit candidates through the CBREX platform, C Screen validates and ranks them, and the shortlist flows into your existing ATS as a pre-screened, ranked candidate pool. Your hiring managers work in the same system they always have, they just receive better candidates at the top of the queue.
For a detailed look at ATS integration in the Indian enterprise context, see our guide on Candidate Screening in 2026: 15 Most-Asked Questions Answered.

AI screening saves the most time in specific conditions. Understanding those conditions helps you set realistic expectations and design your process accordingly.
Where AI screening delivers the biggest time savings:
Where AI screening alone doesn't save enough time:
For Indian mid-market companies hiring across multiple geographies simultaneously, the time savings compound. A TA team managing roles in Singapore, Germany, and the UAE at the same time can't apply consistent human review across all three markets. AI validation provides a consistent quality floor across every geography, while specialist agencies in each market handle the local sourcing. That combination is where the real time-to-hire improvement comes from.
The data on time-to-hire impact is significant. For more on what slow hiring actually costs your business, see our analysis of Time to Hire: The Hidden Cost of Roles Left Open.
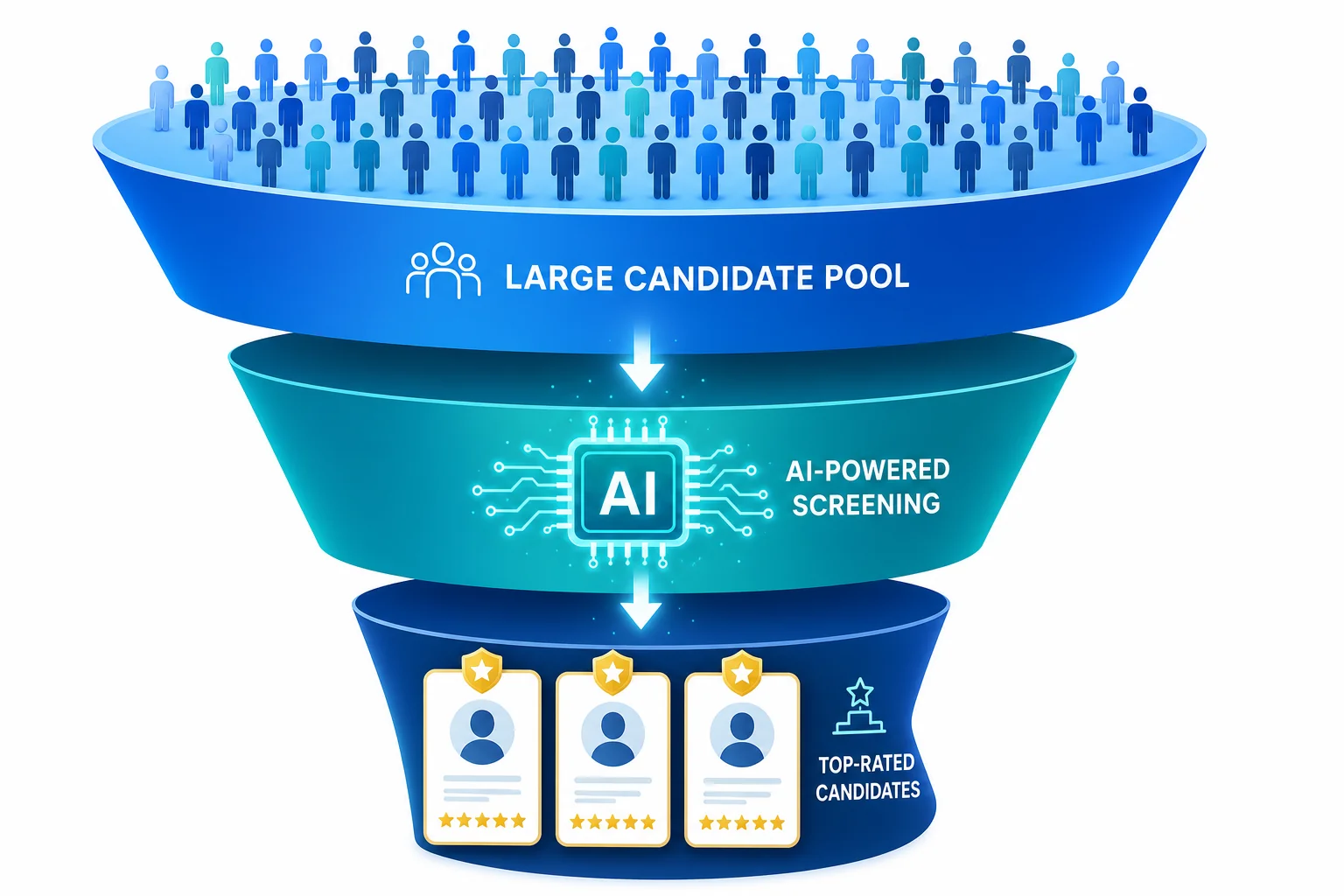
The 3-level screening model is the answer to a problem that neither AI-only nor agency-only approaches solve: how do you consistently produce shortlists where every candidate is genuinely worth interviewing?
Here's how each level works and why it matters:
A specialist recruiting firm with deep domain knowledge in the relevant function and geography reviews candidates before they enter the AI screening layer. This is not a generic recruiter doing a keyword check, it's a specialist who understands the role, the market, and what good looks like for this specific hire.
This layer does two things that AI cannot. First, it reaches passive candidates, people who aren't actively applying but who are the right fit for the role. Second, it applies human judgment to filter out candidates whose CVs look right but whose actual fit is wrong (the AI-optimised CV problem, the career story that doesn't hold up on a call).
The pre-screened candidate pool then goes through C Screen, CBREX's AI validation layer. At this point, the AI isn't working on raw, unfiltered applications, it's working on a pool that has already passed specialist human review. That's a fundamentally different input quality than most AI screeners receive.
C Screen scores each candidate across multiple dimensions against the job requirement, applies consistent criteria across all submissions regardless of which agency sourced the candidate, and produces a ranked output. Candidates who scored well with one agency but poorly against the job criteria are identified. Candidates who were submitted by different agencies but are essentially the same profile are deduplicated.
The hiring manager receives a stack-ranked shortlist. Not a pile of CVs. Not a filtered list. A ranked shortlist where the top candidates have passed both specialist human judgment and AI validation, and where the ranking reflects a consistent, auditable scoring framework.
The practical result: hiring managers spend their time on candidates who are genuinely worth interviewing, not on triage. Interview conversion rates improve. Time-to-hire drops. And because the process is consistent across geographies and agencies, the quality of shortlists doesn't vary based on which agency happened to be most responsive that week.
This model is particularly powerful for Indian companies managing multi-geo hiring. When you're filling roles across North America, MENA, SEA, and EMEA simultaneously, consistent shortlist quality across every market is the difference between a manageable hiring process and chaos. For more on building that kind of global hiring infrastructure, see our guide on Global Hiring from India: The 2026 Complete Guide.
And if you're evaluating whether this model fits your current hiring setup, our post on RPO vs Agency India: Which Model Wins for Mid-Market Companies covers the structural trade-offs in detail.
It depends on the tool. AI screeners built on robust NLP models can parse resumes in multiple languages and interpret qualifications from different national education systems. The key variable is training data, a model trained primarily on English-language resumes from Indian or US candidates will perform less reliably on German, Spanish, or Mandarin CVs. When evaluating a vendor for multi-geo hiring, ask specifically about their multilingual parsing capability and which geographies their training data covers.
AI screening is most reliable as a first-pass filter for senior roles, not as a primary evaluation tool. At the VP and C-suite level, the candidate pool is small, the evaluation criteria are complex, and the cost of a wrong hire is high. AI can help ensure consistency in how candidates are assessed against stated criteria, but it should be paired with deep specialist agency knowledge and structured human assessment. For leadership hiring specifically, the agency pre-screen layer carries more weight than the AI validation layer.
Measure interview-to-offer conversion rate before and after implementing AI screening. If the screener is working, a higher percentage of candidates who reach the interview stage should convert to offers, because the shortlist quality has improved. Also track hiring manager satisfaction with shortlist quality (a simple 1-5 rating per shortlist is sufficient). If those metrics don't improve within three to six months, the screener isn't adding value.
Three inputs matter most: a well-written job description with clear requirements, a sufficient volume of candidate submissions to rank meaningfully, and (over time) feedback data from hiring outcomes to improve the model's accuracy. The job description quality is the most commonly underestimated factor. Vague job descriptions produce vague scoring, the AI can only screen against criteria it's been given.
This is a critical question for any company handling candidate data across multiple jurisdictions. In India, the Digital Personal Data Protection Act (DPDPA) 2023 governs how personal data, including resume data, can be collected, processed, and stored. In the EU, GDPR applies. In the US, various state-level privacy laws are relevant. Any AI screening vendor operating across these jurisdictions needs to demonstrate data localisation capabilities, clear data retention policies, and explicit consent mechanisms. Ask for their data processing agreement and check it against your legal team's requirements before signing.
Done well, AI screening is invisible to candidates, they submit their CV and receive a response faster than they would in a manual process. Done poorly, it creates a black box where candidates receive automated rejections with no explanation. The best implementations combine AI screening speed with human communication: candidates are informed of their status promptly, and those who don't progress receive a clear (if brief) explanation. This matters more than most TA teams realise, candidate experience affects employer brand, and employer brand affects the quality of future applicant pools.
AI candidate screening works, when it's deployed as part of a well-designed process, not as a replacement for one. The technology is genuinely capable of processing volume, applying consistent criteria, and producing ranked shortlists faster than any human team can. But it has real failure modes, real bias risks, and real limitations for niche and senior roles that any honest vendor will acknowledge.
The TA leaders getting the most value from AI screening in 2026 are the ones who've stopped asking "should we use AI?" and started asking "where in our process does AI add the most value, and what human judgment does it need to be paired with?" That's the question the 3-level model answers.
For Indian mid-market companies managing hiring across multiple geographies, where the combination of volume, complexity, and speed pressure is highest, the case for a structured AI-plus-specialist-agency model is particularly strong. The alternative is what most companies are already doing: fragmented agency relationships, inconsistent shortlist quality, and TA teams spending more time on CV triage than on the decisions that actually matter.
If you want to see how the 3-level screening model works in practice for your specific hiring context, book a demo with CBREX and we'll walk through a live example with your actual job requirements. Or if you'd prefer to explore the platform first, sign up and see how C Screen ranks your next shortlist against your current process. You can also reach out directly if you have specific questions about multi-geo screening or ATS integration for your setup.
The best hire for your next critical role probably isn't in your current pipeline. The right screening model is how you find them faster.







